

Checking survey data (1): examine rows, columns, data types, and missing values
In this post, I will cover the steps that I usually take when taking a first look at some survey data with Python.
This post uses data from 2016 OSMI Mental Health in Tech Survey, which is a publicly available Kaggle dataset.
Load Python packages and import data from a csv file
NumPy, Pandas, and Matplotlib are neccessary packages to perform data manipulation and visualization tasks.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('../input/IT_mental_health.csv')
Examine data shape
df.shape
(1433, 63)
The shape of the dataset indicates that there were n=1433 respondents (rows) who participated in the survey and 63 columns of information (columns) collected. That sounds like a pretty long questionnaire that survey methodologist would say no to, since long questionnaires lead to more response burden and that respondents tend to satisfice (e.g. speed through without careful thoughts, choose same answers for subsequent questions). However, it may be okay if there were skipping and branching implemented. Let’s take a look at what the data really looks like.
df.head(3)
| Are you self-employed? | How many employees does your company or organization have? | Is your employer primarily a tech company/organization? | Is your primary role within your company related to tech/IT? | Does your employer provide mental health benefits as part of healthcare coverage? | Do you know the options for mental health care available under your employer-provided coverage? | Has your employer ever formally discussed mental health (for example, as part of a wellness campaign or other official communication)? | Does your employer offer resources to learn more about mental health concerns and options for seeking help? | Is your anonymity protected if you choose to take advantage of mental health or substance abuse treatment resources provided by your employer? | If a mental health issue prompted you to request a medical leave from work, asking for that leave would be: | ... | If you have a mental health issue, do you feel that it interferes with your work when being treated effectively? | If you have a mental health issue, do you feel that it interferes with your work when NOT being treated effectively? | What is your age? | What is your gender? | What country do you live in? | What US state or territory do you live in? | What country do you work in? | What US state or territory do you work in? | Which of the following best describes your work position? | Do you work remotely? | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 26-100 | 1.0 | NaN | Not eligible for coverage / N/A | NaN | No | No | I don't know | Very easy | ... | Not applicable to me | Not applicable to me | 39 | Male | United Kingdom | NaN | United Kingdom | NaN | Back-end Developer | Sometimes |
| 1 | 0 | 6-25 | 1.0 | NaN | No | Yes | Yes | Yes | Yes | Somewhat easy | ... | Rarely | Sometimes | 29 | male | United States of America | Illinois | United States of America | Illinois | Back-end Developer|Front-end Developer | Never |
| 2 | 0 | 6-25 | 1.0 | NaN | No | NaN | No | No | I don't know | Neither easy nor difficult | ... | Not applicable to me | Not applicable to me | 38 | Male | United Kingdom | NaN | United Kingdom | NaN | Back-end Developer | Always |
3 rows × 63 columns
Check rows
As a common practice, I usually first check rows and see if there are any duplicated records. Duplication in survey data suggests that respondents entered exactly same values across all survey questions. For this study, this is likely an error since there are quite a number of questions so chance of natural duplication should be low.
# check for duplication
df.duplicated().sum()
0
Check columns
The first impression after looking at the head of the dataset is that the columns have the full question texts as their names. We can first check whether that’s the case, and if so, we could assign appropriate names to the columns.
question_list = df.columns.to_list()
len(question_list)
63
question_list[0:5] # only show the first five as an example
['Are you self-employed?',
'How many employees does your company or organization have?',
'Is your employer primarily a tech company/organization?',
'Is your primary role within your company related to tech/IT?',
'Does your employer provide mental health benefits as part of healthcare coverage?']
By checking df.columns we know that indeed the data columns are named with their original question texts. We usually would want the column names to be concise yet meaningful. Here we could rename the columns by assigning short phrases as names.
# assign variable names
df.columns = ["self", "employee", "type", "IT", "benefit", "options", "discussion", "learn", "anoymity", "leave", "mental_employer", "physical_employer",
"mental_coworker", "mental_super", "as_serious", "consequence", "coverage", "resources", "reveal_client", "impact", "reveal_coworker",
"impact_neg", "productivity", "time_affected", "ex", "coverage_ex", "options_ex", "discussion_ex", "learn_ex", "anoymity_ex", "mental_employer_ex",
"physical_employer_ex", "mental_coworker_ex", "mental_super_ex", "as_serious_ex", "consequence_ex", "physical_interview", "physical_interview_y",
"mental_interview", "mental_interview_y", "hurt", "negative", "share", "unsupport", "experience", "history", "past", "mental_disorder",
"conditions_diagosed1", "conditions_believe", "diagnose", "conditions_diagosed2", "treatment", "interfere", "interfere_nottreated",
"age", "gender", "country_live", "state", "country_work", "state_work", "position", "remote"]
Looking at df.head(), another thing I noticed is that this dataset does not come with a unique identifier. It probably won’t affect the analysis work too much, but may still cause confusion when for example sorting and/or merging is involved. We could simply use index of the rows as respondent ID.
df["ID"] = df.index + 1
Missing data and data type
The first few rows of the dataframe also shows a number of NaN, suggesting existence of missing values. There are several missing scenarios for survey data: 1) missing due to legitimate skips such as programming skips and branching; 2) missing due to intentional skips/don’t know/refused; 3) systematic missing due to programming errors, usually checked against questionnaire and programming spec. Ideally we would want to distinguish between these missingness to make better analysis decisions.
Checking variable types is also an essential step before carrying out any analysis but is often overlooked. Different types could imply different statistical and visualization choices (will be discussed in more detail in the next post). Here we take a look at the types of variables to help us better understand the questionnaire (in the case no questionnaire is given).
# create a function for summarizing n, number of missing values, variable types, and values of each variable
def summarize_column(data):
valuelist =[]
for col in data.columns:
valuelist.append(data[col].unique())
summarydic = {'variable_name': data.columns,
'n': data.notnull().sum().to_list(),
'n_miss': data.isnull().sum().to_list(),
'values': valuelist,
'variable_type': data.dtypes}
summarydf = pd.DataFrame(summarydic)
return summarydf
summarytable = summarize_column(df)
summarytable[0:5] # only show the first five as an example
| variable_name | n | n_miss | values | variable_type | |
|---|---|---|---|---|---|
| self | self | 1433 | 0 | [0, 1] | int64 |
| employee | employee | 1146 | 287 | [26-100, 6-25, nan, More than 1000, 100-500, 5... | object |
| type | type | 1146 | 287 | [1.0, nan, 0.0] | float64 |
| IT | IT | 263 | 1170 | [nan, 1.0, 0.0] | float64 |
| benefit | benefit | 1146 | 287 | [Not eligible for coverage / N/A, No, nan, Yes... | object |
Looking at the table above I’m already seeing mis-categorize of variable type. For example, the variable “type” and “IT” look like categorical variables that take on levels 1 and 0. We could further edit those back to the desired type.
# create a plot showing the number of missing values summarized by variable
summarytable['n_miss'].value_counts()[1:].plot(kind='bar', figsize=(13,9))
plt.xlabel("number of missing data", labelpad=10, fontsize=14)
plt.xticks(rotation=360)
plt.ylabel("Number of variables", labelpad=10, fontsize=14)
plt.title("Number of variables that have certain number of missing values", y=1.02, fontsize=15)
plt.show()
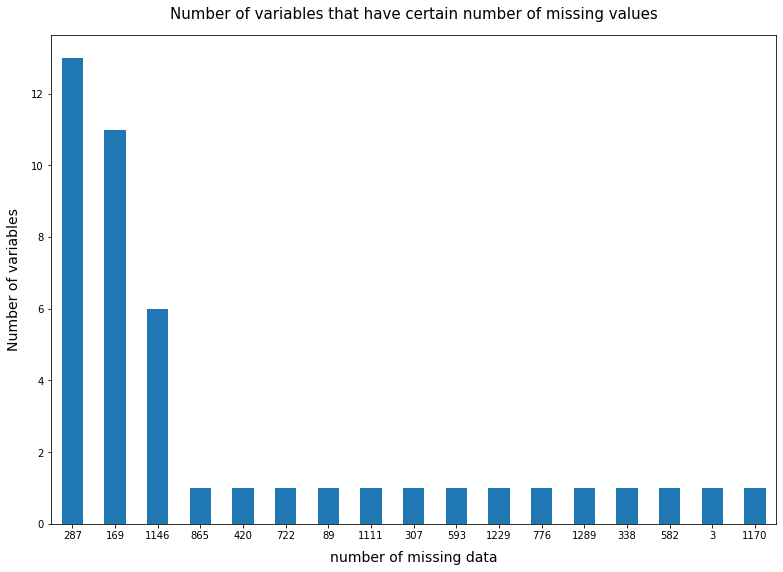
The above bar chart shows some missing pattern - we can see that there are a number of variables that have 287, 169, and 1146 missing data, which implies that this kind of missingness could be due to legitimate skip of survey questions. The rest of the missing values are only specific to certain variables, which could be due to respondent skipping that question (don’t know or refusal). For now, we don’t want to recode or impute for missing values. These procedures are usually carried out with specific analysis intentions.



